Ever wondered if a smaller, more efficient AI model could outsmart its bigger, more expensive cousins? Let me share a fascinating discovery that's changing how we think about AI problem-solving! 🤔
The Traditional Approach vs. The Smart New Way
For quite some time now, companies have been following a simple recipe for better AI: make it bigger, feed it more data, and use more powerful computers. Think of it like building a bigger brain and stuffing it with more information. While this works, it's becoming incredibly expensive – AI companies raising and using billions of dollars! 💰
But here's where it gets interesting. Researchers found a clever alternative: instead of making the AI bigger, why not give it more time to think? Just like how a student might perform better on a test when given extra time to check their work, AI can do better when it has time to consider problems carefully.
Understanding the Two Approaches
The Traditional Way: Train-Time Compute
Train-time compute is like the study time and resources needed to teach the student. Imagine you're teaching someone everything they need to know:
- You need lots of books
- You spend many hours teaching them
- You might need multiple teachers
- You use up lots of energy and time to make sure they learn everything
The Smart New Way: Test-Time Compute
Test-time compute is like what happens when the student actually takes a test. When they get a question:
- They think harder about difficult questions
- They might take more time to double-check their work
- They might look back at different parts of the question
- They might try solving it in different ways
In AI terms, test-time compute is about using more computing power when the AI is actually answering questions or solving problems, rather than during its initial training. It's like giving the AI more time to "think" about its answers.
Instead of spending all your money on teaching (training), you could spend less on teaching but give the student more time to think carefully during the test (using test-time compute). This might be a smarter way to use resources!
Three Clever Ways to Make Small AI Models Punch Above Their Weight(s) 😉
Let's understand Process Reward Models (PRMs) before we dive into the methods
Think of a PRM like a smart teacher who doesn't just look at your final answer, but watches and scores how you solve the problem step by step. 📝
Here's how it works:
Traditional Way (Regular Reward Model)
- Only looks at your final answer
- Gives one score at the end
- Like a teacher who only checks if you got the right answer
Process Reward Model (PRM)
- Watches and scores each step of your work
- Gives feedback throughout the solution process
- Like a teacher who sits with you and says "Yes, that's the right approach" or "Maybe try a different way" at each step
Real-World Example: Solving a Math Problem
The PRM evaluates each step of your solution:
- When you write down the equation ➡️ PRM gives a score
- When you start solving it ➡️ PRM gives another score
- When you simplify terms ➡️ Another score
- When you reach the final answer ➡️ Final score
The advantages of PRMs:
- Can catch mistakes early
- Helps guide the solution process
- Can identify which steps are more promising
- Makes it easier to find the right path to the answer
Technical Definition
A Process Reward Model (PRM) is a learned model that evaluates the quality of intermediate reasoning steps during solution generation, producing a sequence of scores that capture the cumulative quality of the solution trajectory.
More information at: PRM paper on Hugging Face
Experimental Setup
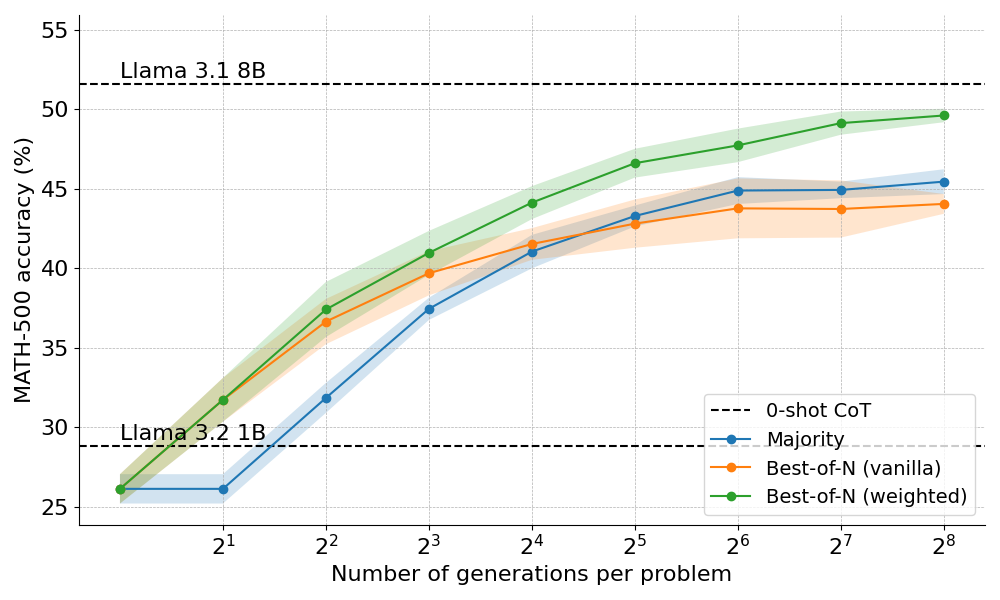
In this exploration of test-time compute scaling, researchers primarily worked with two Llama models:
Llama 3.2 1B: A smaller, more efficient model (1 billion parameters)
Llama 3.1 8B: A larger model used as a benchmark (8 billion parameters)
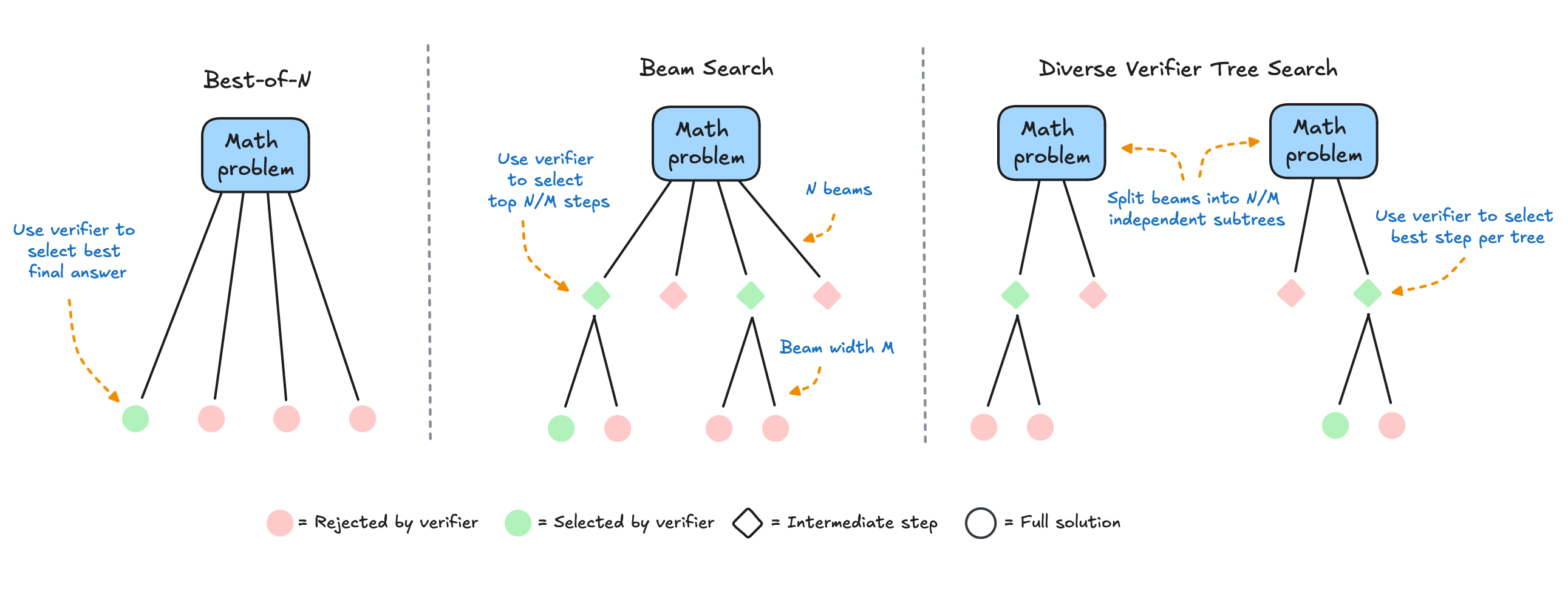
1. The "Multiple Attempts" Method (Best-of-N)
Imagine taking a test where you could try answering each question several times and pick your best answer. That's essentially what this method does! It comes in two flavors:
- Simple version (Vanilla Best-of-N): Try many times, assign scores to each answer, pick the best single answer using a PRM
- Smart version (Weighted Best-of-N): If you get the same good answer multiple times, it's probably right!
2. The "Step-by-Step" Method (Beam Search)
Think of this like solving a complex puzzle. Instead of rushing to the end, the AI:
- Takes careful steps
- Keeps track of multiple possible solutions
- Drops paths that don't look promising (after scoring each step with PRM)
- Continues with the most promising approaches
It's like having a really methodical problem-solver who considers multiple possibilities before moving forward! 🧩

3. The "Different Perspectives" Method (DVTS)
Beam Search performs better than Best-of-N, but tends to underperform on simpler problems and at large test-time compute budgets.
Diverse Verifier Tree Search (DVTS) is the new kid on the block by (Hugging Face). Instead of having multiple similar approaches, this method:
- Tries completely different ways to solve the problem
- Keeps solutions diverse and creative
- Works amazingly well when there's plenty of time to think

The Amazing Results 🌟
Here the researchers have found something incredible. A smaller AI model (imagine a smart student) could actually outperform a much larger one (imagine a math genius) just by thinking more carefully about problems!
Different methods worked better for different situations:
- Simple problems: The "Multiple Attempts" method shined
- Complex problems: The "Step-by-Step" method proved best
- When time wasn't an issue: The "Different Perspectives" method took the crown
Why This Matters (for Business) 💼
This discovery has huge implications:
- Cost Efficiency: You might not need the biggest, most expensive AI to get great results
- Resource Optimization: Smaller models using smarter methods can be just as effective
- Practical Applications: This approach could make advanced AI models more accessible to more businesses
The Bottom Line
Just like in human problem-solving, sometimes it's not about having the most knowledge – it's about taking the time to think things through carefully and trying different approaches. This research shows that by giving AI models more "thinking time" rather than just making them bigger, we can achieve impressive results while keeping costs down.
The future of AI might not be about building bigger and more expensive systems, but about making smarter use of what we already have. It's a bit like the tortoise and the hare – sometimes the slower, more methodical approach wins the race! 🐢✨
💡 Note: This blog post is based on the excellent article "Scaling Test-Time Compute" published on Hugging Face Spaces. All images and core concepts have been adapted from the original work, with the goal of making these ideas more accessible to a broader audience. A big thank you to the Hugging Face team for sharing their research and insights!
For those interested in diving deeper into the technical details and implementation, I highly recommend checking out the original article and accompanying code.